OLEUM Datenbank
In Zeiten zunehmenden Wettbewerbs durch die Globalisierung und das heutige wachsende Kundenbewusstsein für Lebensmittelqualität stehen die Lebensmittelkontrollbehörden weltweit vor der großen Herausforderung, Lebensmittelsicherheit, Authentizität und Qualität zu gewährleisten. Im Rahmen des EU-Projekts H2020 OLEUM werden nicht nur eine Vielzahl etablierter und neuer Analysetechniken untersucht, um harmonisierte Analyseprotokolle zu erstellen. Zusätzlich wird eine Datenbank, die OLEUM-Datenbank, implementiert, um den europäischen Kontrollstellen schließlich eine gemeinsame Plattform zur Verfügung zu stellen, die mit analytischen Daten und relevanten Zusatzinformationen (Metadaten) zu den im Rahmen des Projekts analysierten Referenzölen angereichert ist und erweitert werden kann. Die Verfügbarkeit dieser Daten soll eine effektivere Zusammenarbeit und Kompetenz der autorisierten Qualitätskontrolllabors in Europa und eine bessere globale Harmonisierung ermöglichen. Die OLEUM-Datenbank wird es ermöglichen, den Vergleich zwischen den Experimenten zu erleichtern und zentrale Ergebnisse, Kalibrierkurven oder sogar Spektren und Chromatogramme auszutauschen. Neben Fragen der Architektur der Datenbank ist die Bewältigung heterogener Analysedaten eine große Herausforderung. Die finale Datenbank soll nicht nur den Upload von analytischen Messungen ermöglichen, sondern auch deren visuelle Überprüfung, auch wenn die proprietäre Anbietersoftware, mit der die Daten erzeugt wurden, der überprüfenden Person nicht zur Verfügung steht. Denn bei mehr als 20 verschiedenen Analysetechniken liegen die erzeugten Messungen folglich in mehr als 20 verschiedenen Datenformaten vor, und die Anzahl der Datenformate liegt sogar noch höher, da in den meisten Fällen verschiedene Hersteller Messgeräte für die gleiche Analysetechnik anbieten.
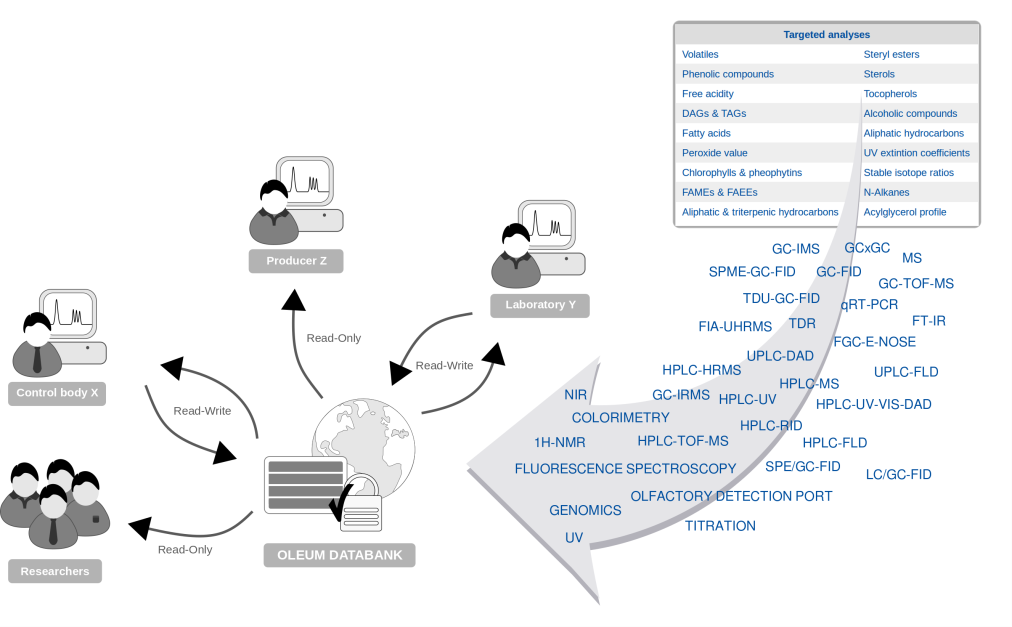
Abbildung 1. Heterogene Analysedaten werden in die OLEUM-Datenbank hochgeladen und zwischen den Beteiligten ausgetauscht.
Der erste Arbeitsabschnitt im Rahmen des Arbeitspaketes 5.3 bestand darin, Beispieldateien mit Rohmessdaten von den an analytischen Aufgaben beteiligten Projektpartnern zu sammeln. Die meisten dieser Dateien sind nicht in einem offenen Format, sondern in dem proprietären Format, das dem Hersteller des Instruments zugeordnet ist, mit dem die Daten erfasst wurden. Einige dieser Dateien konnten bereits von der Software OpenChrom gelesen werden, aber ein erheblicher Teil der Dateien musste dekodiert werden, um sie zugänglich zu machen. Ca. 70% der gelieferten Dateien sind inzwischen vollständig zugänglich und 80% können zumindest teilweise gelesen werden. Die Dekodierung der Formate für Interoperabilitätszwecke ist eine weiterhin andauernde Aufgabe innerhalb des Projektes.
Seit September 2018 ist die Beta-Version der OLEUM-Datenbank online und wird von einigen wenigen Partnern intern ausgewertet. Es ist geplant, allen Projektpartnern im Januar für eine umfassende Evaluierung Zugang zur Datenbank zu gewähren.
Alle in der Datenbank implementierten Softwarekomponenten wurden nach dem Prinzip der Open Source und der besten Wahl für den jeweiligen Zweck ausgewählt. Für die Beta-Version der Datenbank lag der Fokus der aktuell implementierten Benutzeroberfläche auf dem Prozess des Aufbaus und der Verwaltung der zur Verfügung gestellten Daten, so dass die Projektpartner größtmögliche Flexibilität bei der Eingabe der heterogenen Metadaten haben, die den Referenzproben und den verschiedenen Analyseverfahren zugeordnet sind. Da die Datenbank nur dann nützlich sein wird, wenn alle erforderlichen Informationen zusammen mit den Analyseergebnissen zur Verfügung gestellt werden, gibt es derzeit drei Abschnitte für die Datenverwaltung:
- Referenzproben verwalten: Hier fügen die Benutzer die Metadaten von authentischen und anderen Referenzproben hinzu, die mit einer beliebigen Technik analysiert wurden und deren Ergebnisse/Rohdaten bereitgestellt werden sollen. Die Eingabefelder sind voreingestellt, wobei einige obligatorisch und andere optional sind.
- Techniken verwalten: In diesem Bereich können autorisierte Nutzer alle notwendigen Metadatenfelder aufbauen, die für jede relevante Analysetechnik benötigt werden. Da die Metadaten der verschiedenen Techniken sehr unterschiedlich sind, sind die Felder noch nicht voreingestellt. Dies ermöglicht die Erstellung von Abfrageformularen, die so zugeschnitten sind, dass sie die notwendigen Metadaten für die einzelnen bereitgestellten Messdaten sammeln.
- Analysen verwalten: Dieser Abschnitt ist für den eigentlichen Upload von Rohdaten, Ergebnissen, etc. gedacht. Zusätzlich muss der autorisierte Datenlieferant aber auch die Metadaten zur Analyse bereitstellen. Hierzu muss aber vorab das entsprechende Abfrageformular der angewandten Analysentechnik unter dem Abschnitt "Techniken verwalten" zur Verfügung gestellt worden sein.
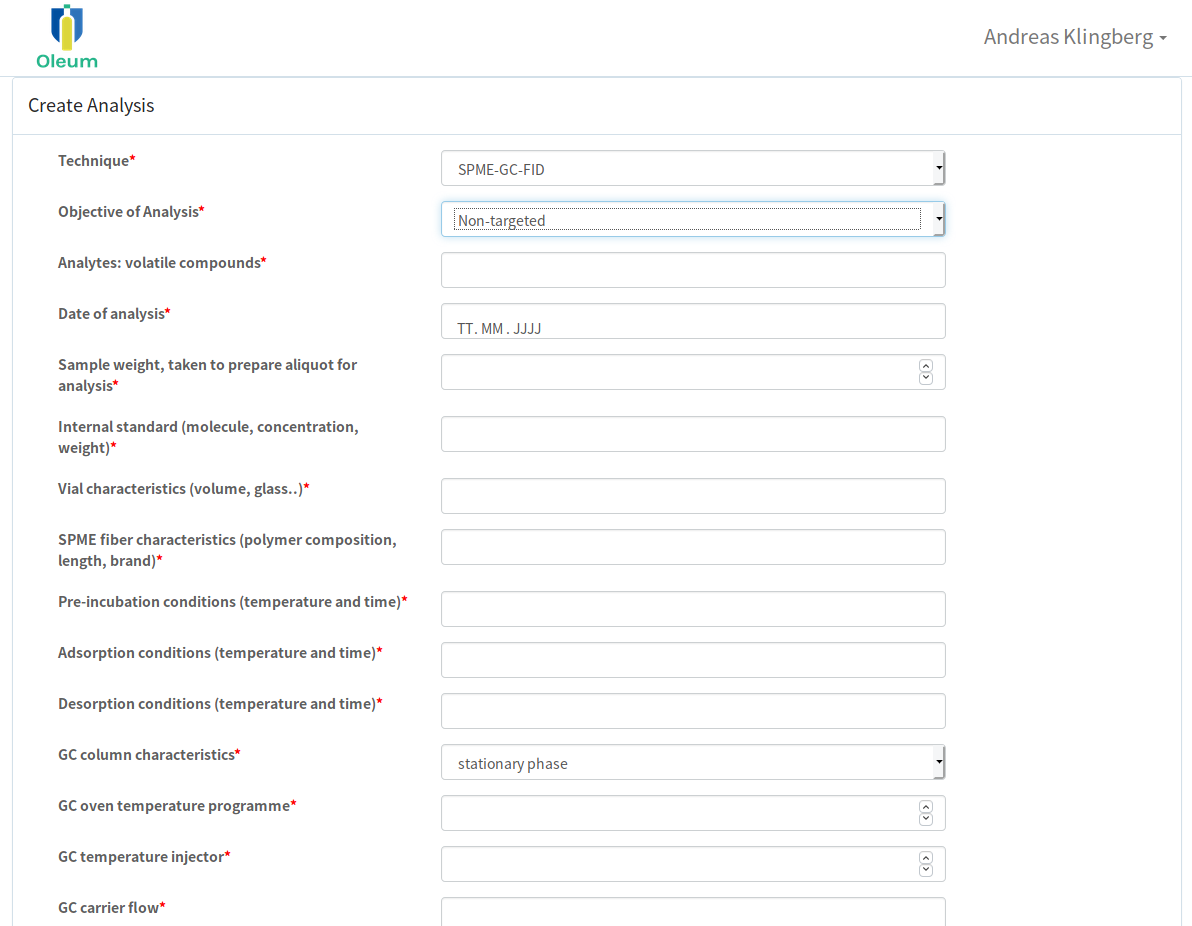
Abbildung 2. Beispiel einer Schnittstelle zur Eingabe von Metadaten für die SPME-GC-FID-Messung.
Darüber hinaus wurde ein Schwerpunkt auf die Benutzerrechteverwaltung gelegt. Es ermöglicht eine Feinjustierung der Zugriffsrechte, die jedem Benutzer vom Administrator zugewiesen werden. Auf den ersten Blick scheint es ausreichend, nur drei verschiedene Benutzerebenen mit festen Benutzerrechten zu haben, "Administratoren" - mit vollem Zugriff auf alle Ebenen, "Datenanbieter" - mit Zugriff auf alle Funktionen zum Hochladen von Daten und "registrierte Benutzer", die nur die in der Datenbank gespeicherten Daten sichten können. Allerdings ist zum jetzigen Zeitpunkt des Projekts noch nicht ganz klar, welche Rechte der "Datenlieferant" und der grundlegende "registrierte Benutzer" erhalten sollen oder ob auch der Zugriff für nicht registrierte Benutzer eingeschränkt werden soll.
Die größte aktuelle Herausforderung in der Datenbankentwicklung ist es, die Daten-Upload-Funktion mit Dateiordnern mit der Größe von 2 bis 4 GB reibungslos zum Laufen zu bringen, was bei Daten der Fall ist, die z.B. von einem GC-QTOF-MS-Gerät erzeugt werden. Allerdings wird dies sicherlich weiterhin stark von der Qualität und Geschwindigkeit der Internetverbindung und des hochladenden Computers abhängen.
Die in diesem Stadium implementierte Schnittstelle für die Datenbankrecherche ist noch sehr einfach gehalten. Auf Basis des Review der Beta-Version durch alle Projektpartner wird in den kommenden Monaten die Implementierung von Datenbanksuch- und Review-Funktionen im Vordergrund stehen.
Andreas Klinberg (Lablicate) and Alain Maquet (JRC-IRMM)