Base de données OLEUM
En cette période de concurrence accrue due à la mondialisation et à la prise de conscience croissante par les clients de la qualité des aliments, les organismes de contrôle des aliments du monde entier sont confrontés au défi majeur d'assurer la sécurité, l'authenticité et la qualité des aliments.
Dans le cadre du projet UE H2020 OLEUM, non seulement un grand nombre de techniques analytiques établies ou nouvelles sont examinées afin de fournir des protocoles analytiques harmonisés.
Une base de données OLEUM est en cours de mise en place afin de fournir aux organismes de contrôle européens une plate-forme partagée contenant des données analytiques ainsi que des informations complémentaires pertinentes (métadonnées) sur les huiles de référence analysées dans le cadre du projet.
La disponibilité de ces données permettra une collaboration et une maîtrise plus efficaces des laboratoires de contrôle de la qualité agréés en Europe et une meilleure harmonisation mondiale.
La banque de données OLEUM permettra de faciliter la comparaison entre expériences en partageant les résultats d'ancrage, les courbes d'étalonnage ou même les spectres ou les chromatogrammes.
Outre les questions relatives à l'architecture de la banque de données, un défi majeur consiste à gérer des données analytiques hétérogènes.
La banque de données doit non seulement permettre le transfert de mesures analytiques, mais également la révision de ces données, même si le logiciel propriétaire du fournisseur ayant acquis les données n'est pas disponible pour la personne qui les examine.
Plus de 20 techniques différentes conduiront à des mesures sauvegardées dans plus de 20 formats de données différents, et le nombre de formats de données pourrait même augmenter du fait que, dans la plupart des cas, différents fournisseurs proposent des appareils de mesure pour la même technique d'analyse.
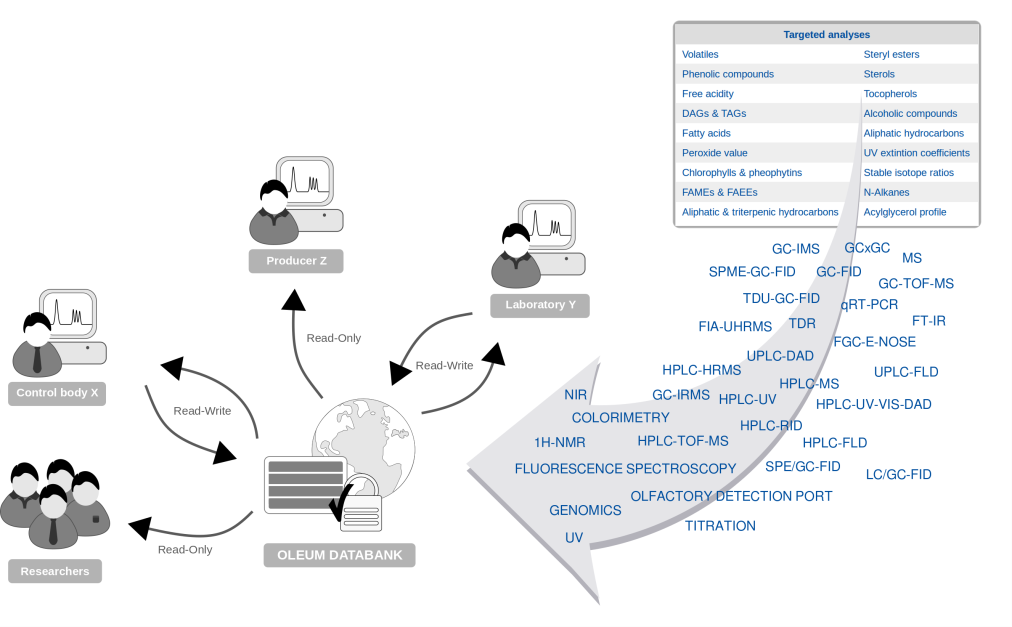
Image 1: Les données analytiques hétérogènes seront transferées dans la banque de données OLEUM et partagées entre les parties prenantes
Le travail initial poursuivi dans le cadre de la tâche 5.3 consistait à rassembler des exemples de fichiers de données brutes de mesure auprès des partenaires du projet impliqués dans des tâches analytiques. La plupart de ces fichiers ne sont dans aucun format ouvert, mais dans le format propriétaire associé au vendeur de l'instrument utilisé pour acquérir les données.
Certains de ces fichiers pouvaient déjà être lus par le logiciel OpenChrom, mais une partie considérable des fichiers devait être décodée pour les rendre accessibles. Jusqu'à présent, environ 70% des fichiers fournis sont entièrement accessibles et 80% au moins peuvent être lus dans une certaine mesure. Le décodage des formats à des fins d'interopérabilité est une tâche continue.
Depuis septembre 2018, la version bêta de la base de données OLEUM est en ligne et est évaluée en interne par quelques partenaires. Il est prévu de donner accès à la base de données à tous les partenaires du projet en janvier pour une large évaluation.
Tous les composants du logiciel mis en œuvre dans la base de données ont été sélectionnés sur la base de leur source ouverte et du meilleur choix en fonction des besoins.
Pour la version bêta de la base de données, l’interface utilisateur actuellement mise en œuvre a mis l’accent sur le processus de constitution et de gestion des données mises à disposition, de sorte que les partenaires du projet disposent de la plus grande flexibilité possible pour saisir les métadonnées hétérogènes associées aux échantillons de référence, ainsi que chacune des différentes procédures analytiques. Gardant à l'esprit que la base de données ne sera utile que si toutes les informations nécessaires sont fournies avec les résultats analytiques, il existe actuellement trois sections pour la gestion des données:
- Gérer les échantillons: les utilisateurs ajoutent ici les métadonnées des échantillons authentiques et d'autres échantillons de référence qui ont été analysés par n'importe quelle technique et dont les résultats / données brutes seront fournis. Les champs de saisie sont prédéfinis, certains étant obligatoires et d'autres facultatifs.
- Gérer les techniques: cette section est destinée à créer tous les champs de métadonnées nécessaires pour chaque technique analytique pertinente. Les métadonnées des différentes techniques étant extrêmement diverses, les champs n’ont pas encore été prédéfinis. Cela permet de créer des formulaires de requête adaptés à la collecte des métadonnées nécessaires pour chaque donnée de mesure fournie.
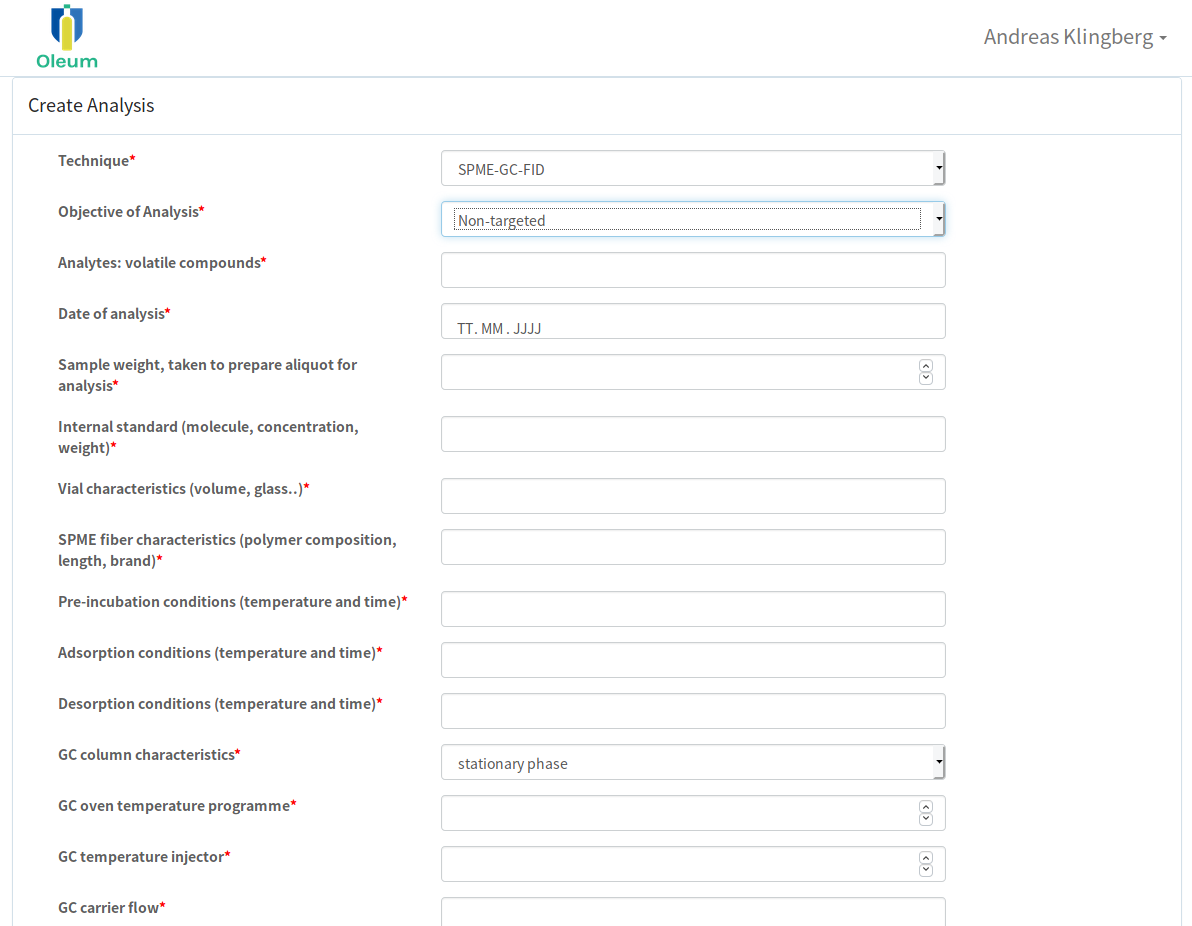
Image 2: Gestion de l'analyse - Exemple d'interface permettant de saisir des métadonnées pour la mesure SPME-GC-FID
- Gérer l'analyse: cette section concerne le transfert effectif des données brutes, des résultats, etc. Mais le fournisseur de données doit en outre fournir les métadonnées de l'analyse. Mais cela n’est possible que si la forme de requête correspondante de la technique analytique appliquée est disponible dans la section "Gérer les techniques".
En outre, la gestion des droits des utilisateurs a fait l’objet d’une attention particulière. Il permet un ajustement précis des droits d'accès accordés à chaque utilisateur par l'administrateur. À première vue, il semble suffisant d’avoir simplement trois niveaux d’utilisateur différents avec des droits d’utilisateur fixes, les «administrateurs» - ayant un accès complet à tous les niveaux, les «fournisseurs de données» - ayant accès à toutes les fonctionnalités permettant le transfert de données et les «utilisateurs enregistrés» - étant seulement capables d'examiner les données contenues dans la base de données.
Mais au stade actuel du projet, les droits du «fournisseur de données» et de «l'utilisateur enregistré» de base ne sont pas encore clairement définis, pas plus que la possibilité aux utilisateurs non enregistrés d’avoir un accès limité.
Le plus grand défi actuel dans le développement de la base de données consiste à faire en sorte que la fonction de transfert de données fonctionne correctement avec des dossiers de données allant jusqu'à 2 à 4 Go, ce qui est le cas des données générées, par exemple par un appareil GC-QTOF-MS. Cependant, cela restera certainement très dépendant de la qualité et de la vitesse de la connexion Internet et de l'ordinateur utilisé pour le transfert.
L'interface de recherche dans la base de données mise en œuvre à ce stade est toujours basique. Sur la base de l’examen de la version bêta par tous les partenaires du projet, la mise au point de capacités de recherche et d’examen dans la base de données sera l’objectif principal au cours des prochains mois.
Andreas Klinberg (Lablicate) and Alain Maquet (JRC-IRMM)