Banco de datos de OLEUM
En tiempos de creciente competencia debido a la globalización y con la cada vez mayor preocupación de los consumidores sobre la calidad de los productos alimenticios, los organismos de control de alimentos de todo el mundo se enfrentan al gran desafío de garantizar la seguridad, la autenticidad y la calidad de los mismos. Como parte del Proyecto EU H2020 OLEUM, no solo se están examinando un gran número de técnicas analíticas, tanto ya establecidas como nuevas, para entregar protocolos analíticos estandarizados. También se está implementando una base de datos, el banco de datos OLEUM, para proporcionar en último término a los organismos de control europeos una plataforma compartida que contenga datos analíticos junto con información adicional relevante (metadatos) sobre aceites de referencia analizados como parte del proyecto. La disponibilidad de estos datos permitirá una colaboración y un rendimiento más eficaces de los laboratorios de control de calidad autorizados en Europa y una mejor armonización global. El banco de datos OLEUM permitirá facilitar la comparación entre experimentos, compartiendo resultados de base, rectas de calibrado o incluso espectros o cromatogramas. Aparte de las cuestiones relacionadas con el diseño del banco de datos, un desafío importante es hacer frente a los datos analíticos heterogéneos. El banco de datos no solo debería permitir la subida de mediciones analíticas, sino que también debería revisarlas, incluso si el software propietario del proveedor que adquirió los datos no está disponible para el revisor. Más de 20 técnicas diferentes darán lugar a medidas guardadas en más de 20 formatos de datos diferentes y la cantidad de formatos de datos puede incluso aumentar debido al hecho de que, en la mayoría de los casos, diferentes proveedores ofrecen dispositivos de medición para la misma técnica analítica.
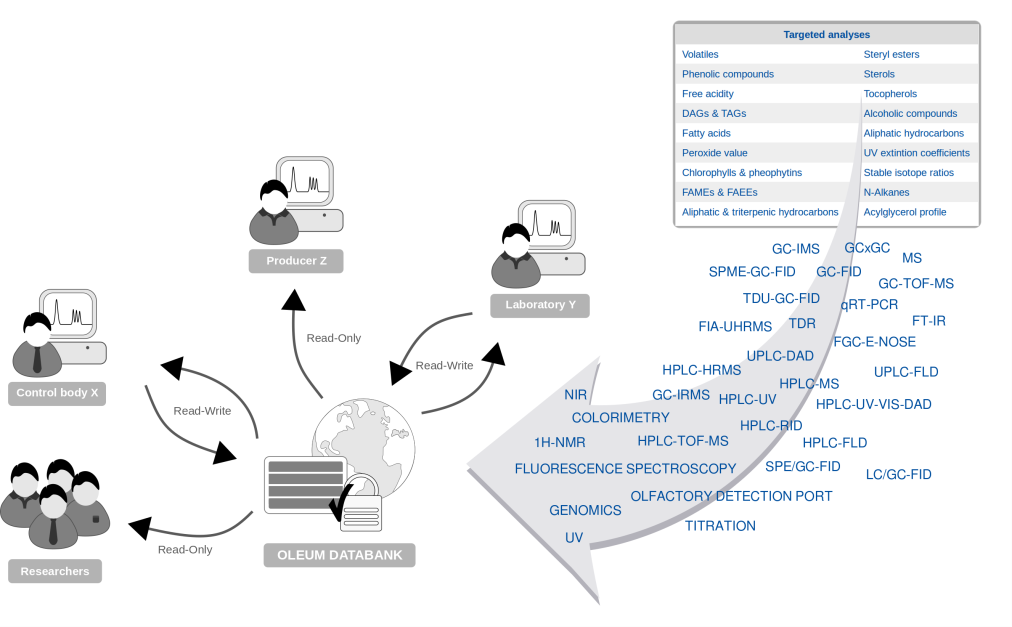
Figura 1: Los datos analíticos heterogéneos se cargarán en el banco de datos de OLEUM y se compartirán entre las partes interesadas.
El trabajo inicial perseguido dentro de la tarea 5.3 fue recopilar archivos de ejemplo de datos de medición sin procesar de los socios del proyecto involucrados en tareas analíticas. La mayoría de estos archivos no están en ningún formato abierto, sino en el formato propietario/privativo asociado al proveedor del instrumento utilizado para adquirir los datos. Algunos de esos archivos podían leerse ya con el software OpenChrom, pero una parte considerable de los archivos debían decodificarse para hacerlos accesibles. Aproximadamente se puede acceder de manera total al 70% de los archivos proporcionados hasta ahora y el 80% se puede leer al menos hasta cierto punto. La decodificación de los formatos para propósitos de interoperabilidad es una tarea continua.
Desde septiembre de 2018, la versión beta del banco de datos de OLEUM está online y es evaluada internamente por unos pocos socios. Se planea dar acceso a la base de datos a todos los socios del proyecto en enero para una evaluación amplia.
Todos los componentes de software implementados en la base de datos se seleccionaron sobre la base de ser de código abierto y la mejor opción para satisfacer el propósito. Para la versión beta de la base de datos, el enfoque de la actual interfaz de usuario implementada ha estado en el proceso de creación y gestión de los datos que se ha puesto a disposición, de modo que los socios del proyecto tengan la mayor flexibilidad posible para introducir los metadatos heterogéneos asociados con las muestras de referencia y con cada uno de los diversos procedimientos analíticos. Teniendo en cuenta que la base de datos solo será útil si se proporciona toda la información necesaria junto con los resultados analíticos, actualmente hay tres opciones para la gestión de datos:
- Gestionar Muestras: Aquí los usuarios agregan los metadatos de muestras auténticas y otras de referencia que han sido analizadas por una técnica en concreto y cuyos resultados/datos en bruto se van a proporcionar/predecir. Los campos de entrada están preestablecidos, siendo algunos obligatorios y otros opcionales.
- Gestionar Técnicas: Esta sección está destinada a construir todos los campos de metadatos necesarios para cada técnica analítica relevante. Dado que los metadatos de las diversas técnicas son extremadamente diversos, los campos aún no han sido preestablecidos. Esto permite crear formularios de consulta que se adaptan para recopilar los metadatos necesarios para cada información de medición proporcionada.
- Gestionar Análisis: Esta sección es para la carga real de datos en bruto, resultados, etc. Pero, además, el proveedor de datos debe proporcionar los metadatos en el análisis. Sin embargo, esto solo es posible si la forma de consulta de la técnica analítica correspondiente aplicada se ha habilitado en la sección "Gestionar Técnicas".
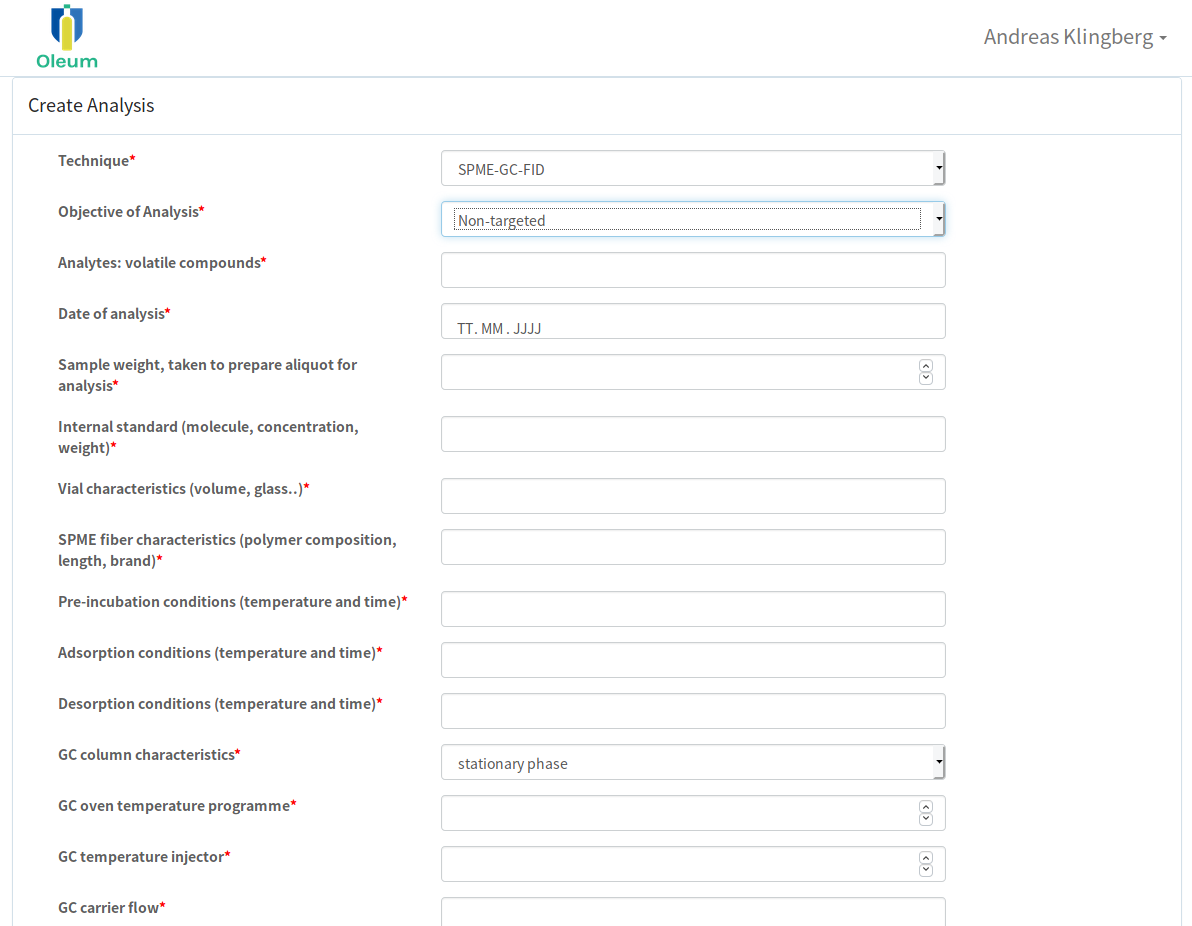
Figura 2: Gestionar Análisis – Ejemplo de interfaz para introducir metadatos para la medición por SPME-GC-FID.
Además, se ha puesto atención en la gestión de los derechos de los usuarios. Eso permite un ajuste fino de los derechos de acceso otorgados a cada usuario por el administrador. A priori, parece suficiente tener simplemente tres niveles de usuario diferentes con derechos de usuario fijos, "administradores" -que tienen acceso completo a todos los niveles-, "proveedores de datos"-con acceso a todas las funciones que permiten la carga de datos- y "usuarios registrados" –que solo pueden revisar los datos contenidos en la base de datos. Pero en la etapa actual del proyecto aún no está completamente claro qué derechos deben otorgarse al "proveedor de datos" y al "usuario registrado" básico o si también debería haber un acceso limitado para los usuarios no registrados.
El mayor desafío actual en el desarrollo de la base de datos es lograr que la función de carga de datos funcione sin problemas con carpetas de datos de 2 a 4 GB, lo que ocurre con los datos generados, por ejemplo, por un dispositivo GC-QTOF-MS. Sin embargo, esto seguirá dependiendo altamente de la calidad y de la velocidad de la conexión a Internet y del ordenador de carga.
La interfaz para la búsqueda en la base de datos implementada en esta etapa aún es básica. Sobre la base de la revisión de la versión beta realizada por todos los socios del proyecto, la implementación de las capacidades de búsqueda y revisión de la base de datos será el enfoque principal en los próximos meses.
Andreas Klinberg (Lablicate) y Alain Maquet (JRC-IRMM)